HPC-X 2.0 Boosts Performance of Grid Benchmark
- Gerardo Cisneros-Stoianowski (Unlicensed)
- Ophir Maor
This post describes how the performance of GRID benchmark built with HPC-X 2.0 was enhanced by enabling UCX.
References
- Grid Testing and Profiling
- Grid: data parallel library for QCD
- Grid: A next generation data parallel C++ QCD library
- Grid on Github
- Understanding Tag Matching Offload on ConnectX-5 Adapters
Overview
What is GRID
Grid is a C++ library, Developed by Peter Boyle (U. of Edinburgh) et al, for Lattice Quantum Chromodynamics (Lattice QCD) calculations that is available on github and is designed to exploit parallelism at all levels:
- SIMD (vector instructions)
- OpenMP (shared memory parallelism)
- MPI (distributed memory parallelism through message passing)
Building the library is straightforward. A number of tests and benchmarks are built along with it. While building the library it also compiles a set of tests and benchmarks, one of which exercises the library thoroughly and prints out performance information.
HPC- X
HPC-X is the Mellanox application accelerator software package that includes the communications libraries you need to get the most out of your Mellanox InfiniBand interconnect. The package may be downloaded here. Building and running applications with OpenMPI and other support libraries that are provided in HPC-X is easy, as the following write-up shows.
- UCX introduced two new accelerated transports, dc_x and rc_x, that use enhanced verbs.
- The best transports for GRID turned out to be rc_x and rc
- In the mpirun example, we enabled hardware tag matching (UCX_RC_VERBS_TM_ENABLE=y) that perform the tag matching lookup in hardware instead of software.
- The selection of a pml (point-to-point management layer): UCX pml and the MXM pml are mutually exclusive; thus, MXM was disabled
Setup
Configuration
Obtaining Grid
1. Download Grid from Github. You can either download the zip file or clone the software directly onto your system. For the DiRAC benchmark, a slightly different tarball was provided.
wget https://github.com/paboyle/Grid/archive/dirac-ITT-fix1.tar.gz tar zxvf dirac-ITT-fix1.tar.gz cd Grid-dirac-ITT-fix1 ./bootstrap.sh
2. Read the readme.md file to find out about building Grid for your specific system. Here we show the procedure we followed in building Grid with the Intel C++ compiler and either OpenMPI from HPC-X 2.0 or Intel MPI.
The last line in the code block above does initial set-up (obtaining the Eigen package and generating the configure script).
Note: Grid requires two packages to be already installed: GMP (https://gmplib.org/) and MPFR (http://www.mpfr.org/).
Building GRID
Bulding GRID with HPC-X 2.0 (accelerated Open MPI)
1. Set up your environment. On our systems, the sysadmins have helpfully provided a set of software modules that set up various environment variables using the module command:
module purge module load intel/compiler/2017.5.239 hpcx-2.0/icc-2017 export OMPI_CXX=icpc
2. Create the directory where the library and programs will be built and configure the build for your system:
mkdir build_hpcx cd build_hpcx ../configure --enable-precision=single --enable-simd=AVX2 --enable-comms=mpi3 --enable-mkl CXX=mpicxx --prefix=/<path-to-installation-directory>/Grid_hpcx20
Note: The specific benchmark for which this effort was carried out required running in single precision; however, double precision tests were also made.
3. Build the library and the benchmarks, run the tests and install the library and the benchmarks:
make 2>&1 | tee make_i17hpcx20.log make check 2>&1 | tee check_i17hpcx20.log make install 2>&1 | tee install_i17hpcx20.log
Note: If your build node has processors that differ from those on compute nodes (e.g., they do not support the SIMD model chosen in the configuration step above) the check and install steps will fail. In that case you may copy the Benchmark_ITT executable from benchmark (under build_hpcx) to any suitable directory.
Note: AVX512 and KNL are among the other possible options for --enable-simd
If the three make steps succeed, you will have bin, lib and include subdirectories under the installation directory you provided in the configure script (--prefix option on step 2 above).
Bulding GRID with Intel MPI
1. Set up your environment, load the intel compiler and intel mpi modules:
module purge module load intel/compiler/2017.5.239 intel/impi/5.1.3.258
2. Create the directory where the library and programs will be built and configure the build for your system:
mkdir build_impi cd build_impi ../configure --enable-precision=double --enable-simd=AVX2 --enable-comms=mpit-auto --enable-mkl CXX=icpc MPICXX=mpiicpc --prefix=/<path-to-installation-directory>/Grid_impit
3. Build the library and the benchmarks, run the tests and install the library and the benchmarks
make 2>&1 | tee make_i17impit.log make check 2>&1 | tee check_i17impit.log make install 2>&1 | tee install_i17impit.log
Note: It may be neccessary to add -lrt to the end of the line starting with "LIBS =" in each of sixteen Makefile files ({,*/,*/*/}Makefile).
Note: If your build node has processors that differ from those on compute nodes (e.g., they do not support the SIMD model chosen in the configuration step above) the check and install steps will fail. In that case you may copy the Benchmark_ITT executable from benchmark (under build_impi) to any suitable directory.
Note: AVX512 and KNL are among the other possible options for --enable-simd
Executing the Benchmark
The Benchmark_ITT executable requires several arguments, most notably
--mpi M.N.P.Q,--shm size--threads nthreads--shm-hugetlb (for Xeon Phi runs)
where M.N.P.Q is the decomposition of a 4-dimensional grid among MPI ranks (so that M*N*P*Q must be equal to the total number of MPI ranks to be spawned by the mpirun command), size is the size of shared memory segments to be used by the program (1024 worked for 4 and fewer nodes; 2048 for 8 and larger up to 128) and nthreads is the number of OpenMP threads per MPI rank, so that M*N*P*Q*nthreads is equal to the total number of cores used during the run.
I ran the programs using the slurm scheduler. For the HPC-X 2.0 executable, the mpirun command was as follows:
/usr/bin/time -p mpirun -np $ranks --map-by ppr:$rpn:node --bind-to $object -report-bindings --display-map \ -mca coll_hcoll_enable 0 -mca mtl ^mxm -x UCX_RC_VERBS_TM_ENABLE=y -mca pml ucx -x UCX_TLS=$transport,self,shm \ /home/gerardo/Grid_hpcx20/bin/Benchmark_ITT --mpi M.N.P.Q --shm 2048 --threads $nthreads
Where:
$ranks is the total number of MPI ranks,
$rpn is the number of MPI ranks per node (at most equal to the number of cores in a node divided by the number of OpenMP threads),
$object is none if $rpn is equal to 1 and socket otherwise,
$transport is rc or rc_x,
M.N.P.Q is the rank decomposition (M*N*P*Q == $ranks and M > N > P > Q), and
$threads is the number of OpenMP threads.
MPI Application Profiling
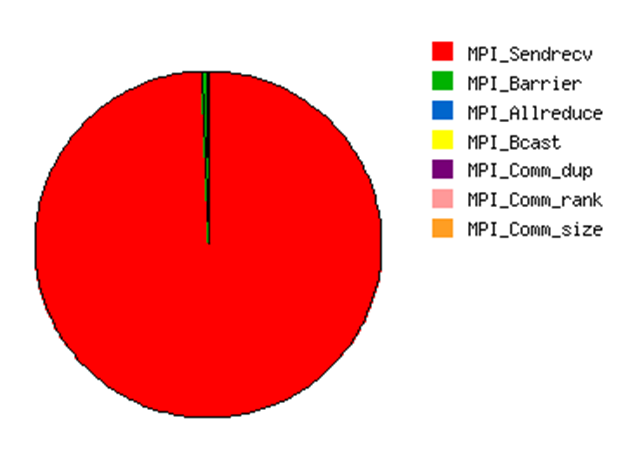
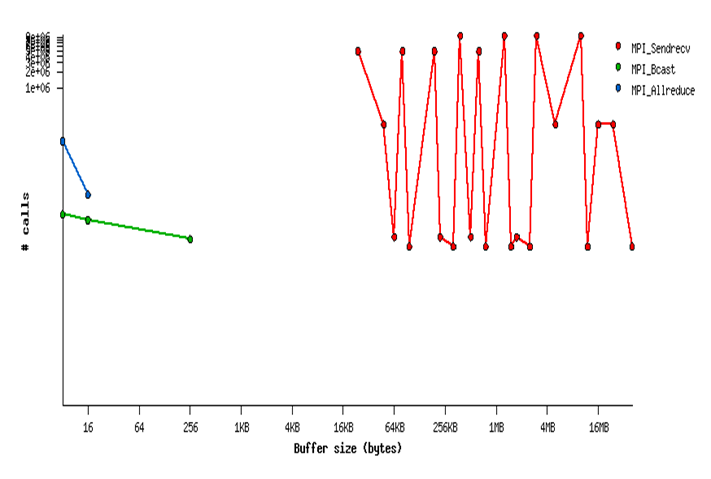
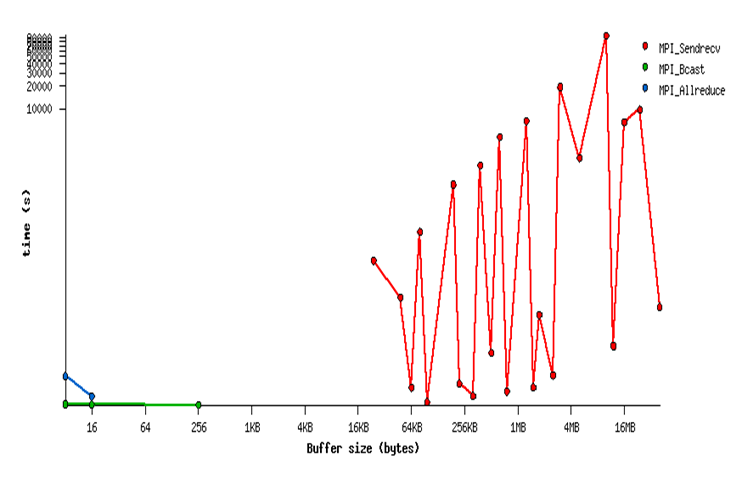
In this case, we used IPM 2.06 to profile the application, as it can be seen, it uses mostly MPI SendReceive operations.
Results
Output Example
At the end of the run, Benchmark_ITT writes a Memory benchmark results table, a Communications benchmark results table (for runs on two or more nodes) and an overall floating point report.
Here is an example:
================================================================================================================= Memory benchmark ================================================================================================================= ================================================================================================================= = Benchmarking a*x + y bandwidth ================================================================================================================= L bytes GB/s Gflop/s seconds GB/s / node ---------------------------------------------------------- 8 50331648.000 4371.720 364.310 1.492 273.232 12 254803968.000 3818.499 318.208 1.708 238.656 16 805306368.000 5851.782 487.649 1.115 365.736 20 1966080000.000 5225.404 435.450 1.248 326.588 24 4076863488.000 2918.898 243.242 2.235 182.431 28 7552892928.000 3062.299 255.192 2.129 191.394 32 12884901888.000 2952.386 246.032 2.208 184.524 36 20639121408.000 2824.411 235.368 2.309 176.526 40 31457280000.000 2825.827 235.486 2.304 176.614 44 46056603648.000 2798.276 233.190 2.321 174.892 48 65229815808.000 2801.425 233.452 2.328 175.089 ================================================================================================================== Communications benchmark ================================================================================================================== ================================================================================================================== = Benchmarking threaded STENCIL halo exchange in 4 dimensions ================================================================================================================== L Ls bytes MB/s uni (err/min/max) MB/s bidi (err/min/max) 4 8 49152 1472.6 178.3 88.9 2531.4 2945.2 356.6 177.9 5062.9 8 8 393216 6147.1 605.2 381.8 8886.2 12294.2 1210.3 763.6 17772.5 12 8 1327104 8722.7 270.0 1960.3 9909.9 17445.3 539.9 3920.5 19819.8 16 8 3145728 9456.4 77.4 3753.1 10058.3 18912.8 154.8 7506.2 20116.6 20 8 6144000 9475.3 61.0 4976.9 10245.7 18950.5 121.9 9953.8 20491.4 24 8 10616832 9499.0 47.4 4991.3 10102.0 18998.1 94.8 9982.5 20204.1 28 8 16859136 9340.3 45.1 4918.4 9866.6 18680.5 90.3 9836.9 19733.2 32 8 25165824 9320.1 47.7 4917.7 9949.8 18640.2 95.4 9835.4 19899.5 ================================================================================================================== Per Node Summary table Ls=16 ================================================================================================================== L Wilson DWF4 DWF5 8 3895.6 33637.9 35835.8 12 13308.6 74021.3 91408.2 16 35034.3 85631.9 114475.0 24 76632.2 98933.4 133285.8 ================================================================================================================== ================================================================================================================== Comparison point result: 79826.6 Mflop/s per node Comparison point is 0.5*(85631.9+74021.3) Comparison point robustness: 0.819 ==================================================================================
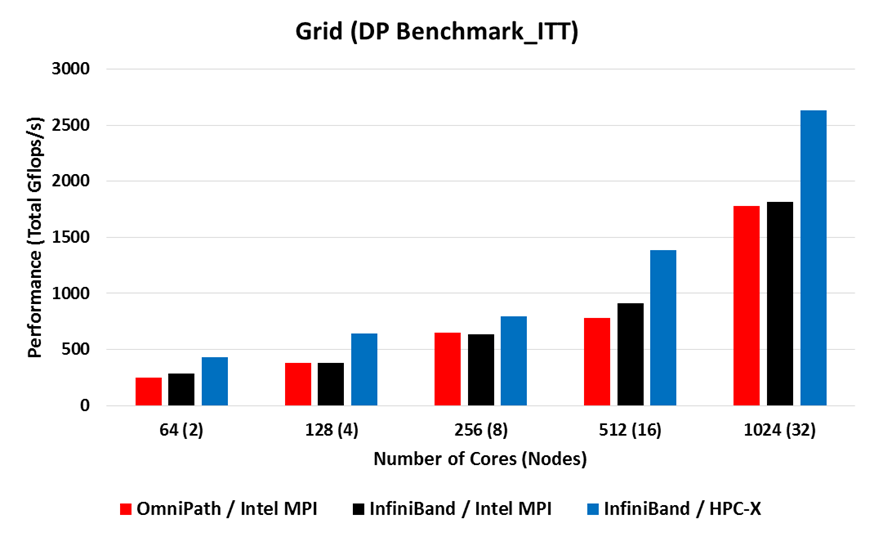
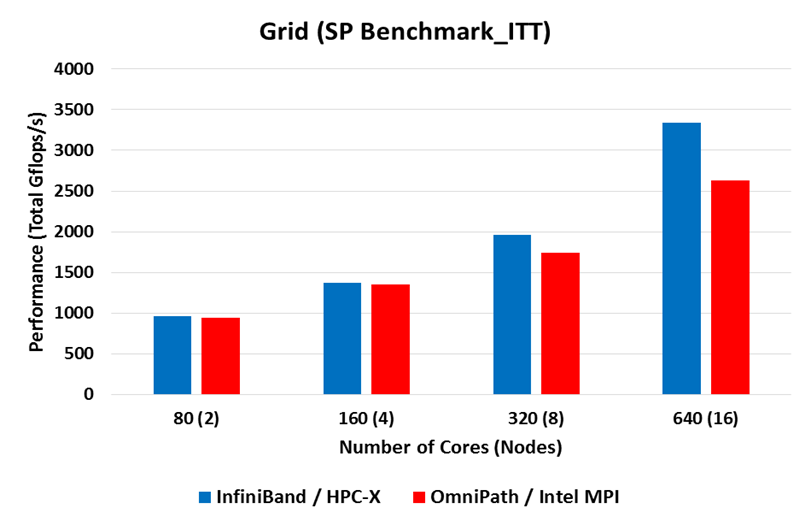
- GRID was built and run using Intel 2017 compilers and HPC-X 2.0 and Intel MPI. The Intel MPI version was run on both InfiniBand (EDR) and OmniPath (OPA).
- The benchmark program prints a "Comparison point result" at the end of the run that is given in Mflop/s per node
- The bars in the diagrams below were obtained by multiplying the performance per node by the number of nodes and converting to Gflop/s.
Single vs. Double Precision
Single Precision numbers uses 32 bits while Double Precision numbers uses 64 bits
The double precision calculations generates more data transfers for the same test size.
The differences in the results presented later emphasis the need for fast accelerated interconnect for best performance.
Performance
Double Precision on Thor
Single Precision on Helios
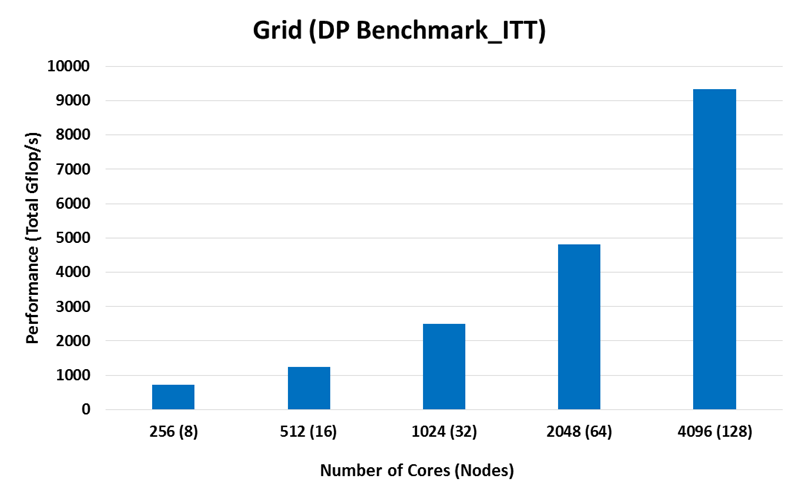
Double Precision Performance on Large Scale
- Intel Xeon E5-2697A v4 (Broadwell)
- Interconnect: EDR InfiniBand
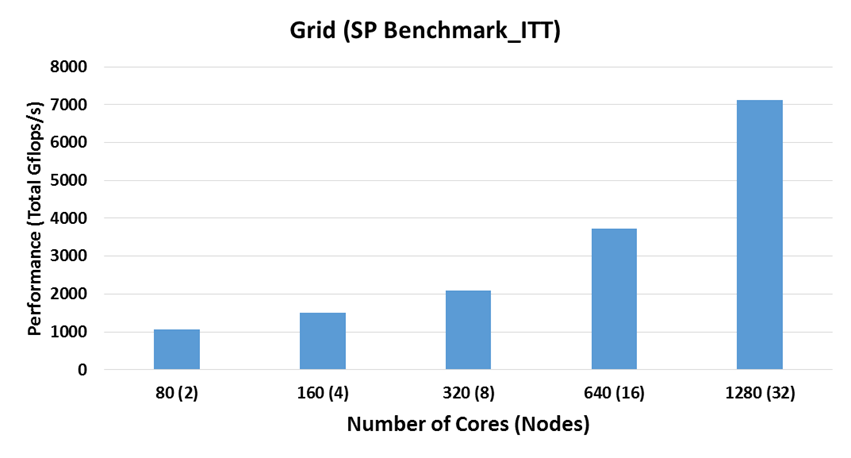
Single Precision Performance on Large Scale
- Intel Xeon Gold 6148 (Skylake)
- Interconnect: EDR InfiniBand
Related articles